Why Ragnerock?
Data is useless if you can't act on it
For practical purposes, data your team can't query doesn't exist. It doesn't matter where or what that data is: If there's no way to get the information out and into your data platform, it's invisible. Ragnerock makes any data source queryable inside your existing infrastructure, and curates that data context for AI-assisted analysis.

Data-driven AI
AI has made data extraction cheap
It used to be expensive to turn raw data into something useful. Organizations sourced data from vendors, or built bespoke in-house pipelines for high-value targets. Only the best-resourced firms could afford to play.
"The work that used to take a team of MLEs six months can be done in an afternoon."
That cost has dropped by orders of magnitude. Frontier AI models can now do topic classification, sentiment analysis, entity extraction, document parsing, and information extraction out of the box.
- Research and analysis. Structure reports, assessments, and evaluations into queryable data: key findings, methodology, conclusions, and recommendations that flow directly into your analytical workflows.
- Regulatory and compliance documents. Extract obligations, risk factors, and material changes from filings, policies, and disclosure documents, automatically, across thousands of files.
- Contracts and operational documents. Parse agreements, correspondence, and operational records to extract terms, entities, timelines, and obligations at scale.
There is useful, queryable data locked inside sources that were previously too expensive to process systematically. That data is now accessible, and the cost of extraction continues to fall.
The new constraint isn't AI capability. It's the ability to operationalize it.
The models exist. Ragnerock gives you the platform to deploy them systematically, and with the orchestration, provenance, and data integration that production research requires.
Context curation for data analysis
Deploying intelligence effectively is a context problem
AI output quality depends on input context. Cursor proved this for code: it manages what the model sees (relevant files, definitions, conventions) so the model produces useful output instead of generic suggestions. The model is interchangeable; the product is the context architecture.
Data work requires fundamentally different context. The inputs that matter are source data, output schemas, and prior analytical results. A model needs the specific input, task taxonomy, and examples of correct output. Generic AI tools don't curate any of this.
Ragnerock curates data context. Each AI agent sees one input and one task, validated against a defined schema. Outputs from upstream agents become context for downstream agents. The system produces queryable, validated data that persists in your infrastructure.
Teams are already building LLM-powered data pipelines in-house. Ragnerock gives those pipelines the context management, orchestration, and auditability that production workloads require.
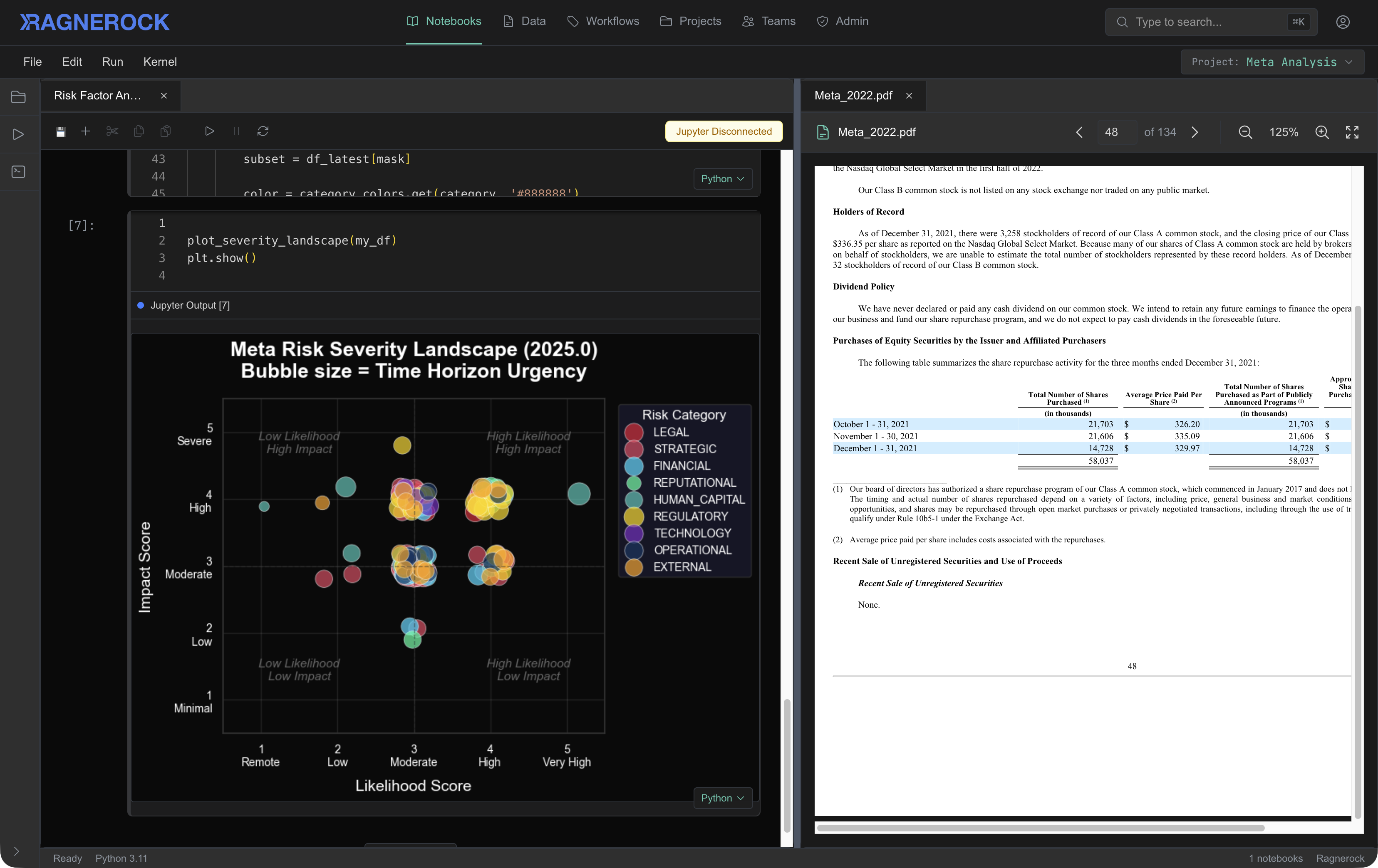
Intelligence from your data
What it takes to make data actionable
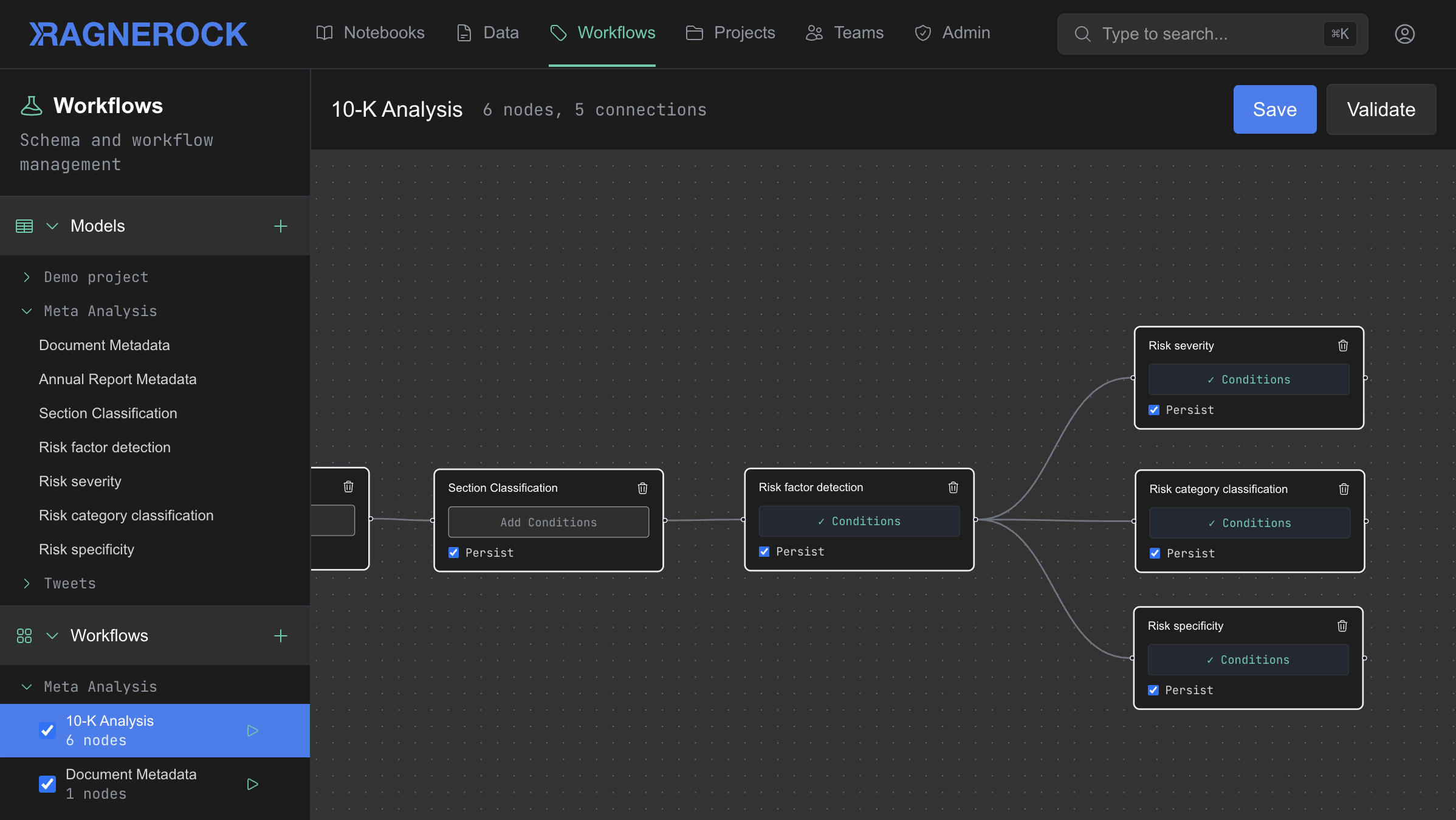
Making data actionable takes four capabilities that reinforce each other. Defined schemas feed orchestration. Validated outputs persist as queryable data. Persisted results become context for downstream analysis. Together, they form a context curation architecture where each layer makes the next one more effective.
Ragnerock integrates all four on top of your existing infrastructure. Define your analytical logic once; the platform handles the rest.
- Define
- AI agents produce reliable output only when their context is precisely scoped. Each agent receives one input and one task, with a defined data contract: input schema, output schema, and validation rules.
- Orchestrate
- Useful analysis is rarely a single step. Workflows chain agents into pipelines where each step consumes validated output from the prior step. They run automatically when new data arrives, or on demand.
- Persist
- Running inference on every query is slow, expensive, and non-deterministic. Results persist as queryable annotations in your data lake, with full traceability to source, operator, model, and prompt.
- Query
- Data is only actionable if your team can get to it with the tools they already use. Standard SQL, semantic search, or a conversational agent. Millisecond latency on pre-computed results.
From prototype to production, no handoff
The workflow your analyst builds to explore a hypothesis on Monday is the same workflow running in production on Friday. When a research question proves valuable, it's already operating at scale.
Concrete gains for analysts and researchers
Explore new frontiers

Research velocity
Test more hypotheses per unit of time and budget.
Investigating a new data source used to mean weeks or months of custom development before you could even evaluate the signal. With Ragnerock, that collapses to days of workflow configuration. The research ideas that weren't worth the effort at $50K of engineering time become worth investigating at $2K.

Your logic, your schema
Intelligence built on your questions, not a vendor's.
When you buy structured data from a vendor, you inherit their schema, their methodology, and their update cadence. Ragnerock lets your team define the extraction logic from scratch: what gets pulled, how it's structured, when it refreshes.
Full provenance
Auditable by design.
Every annotation traces back to source. Every workflow step is logged. Every model call is recorded. When your risk team, your compliance team, or a regulator asks how a data point was derived, the full chain of custody is already captured.
Augment your data lake
Additive to your stack. Not a replacement for any of it
Ragnerock outputs flow into the data infrastructure you've already provisioned. Source documents stay in your buckets, under your security policies.
Bring your own AI provider keys. Your team's existing Python workflows keep working. Ragnerock adds the data layer underneath.





