Extract structured data from your firm's raw data sources.
Most organizations have large volumes of raw data that never make it into a research pipeline. Ragnerock turns that data into structured, queryable results your team can act on.
Lower the cost of exploring new signals
Explore
The value of investigating a new signal is uncertain, but the cost of finding out is high. Ragnerock collapses the cost of exploration so that work that wasn't worth investigating at $50K of effort becomes worth investigating at $2K.
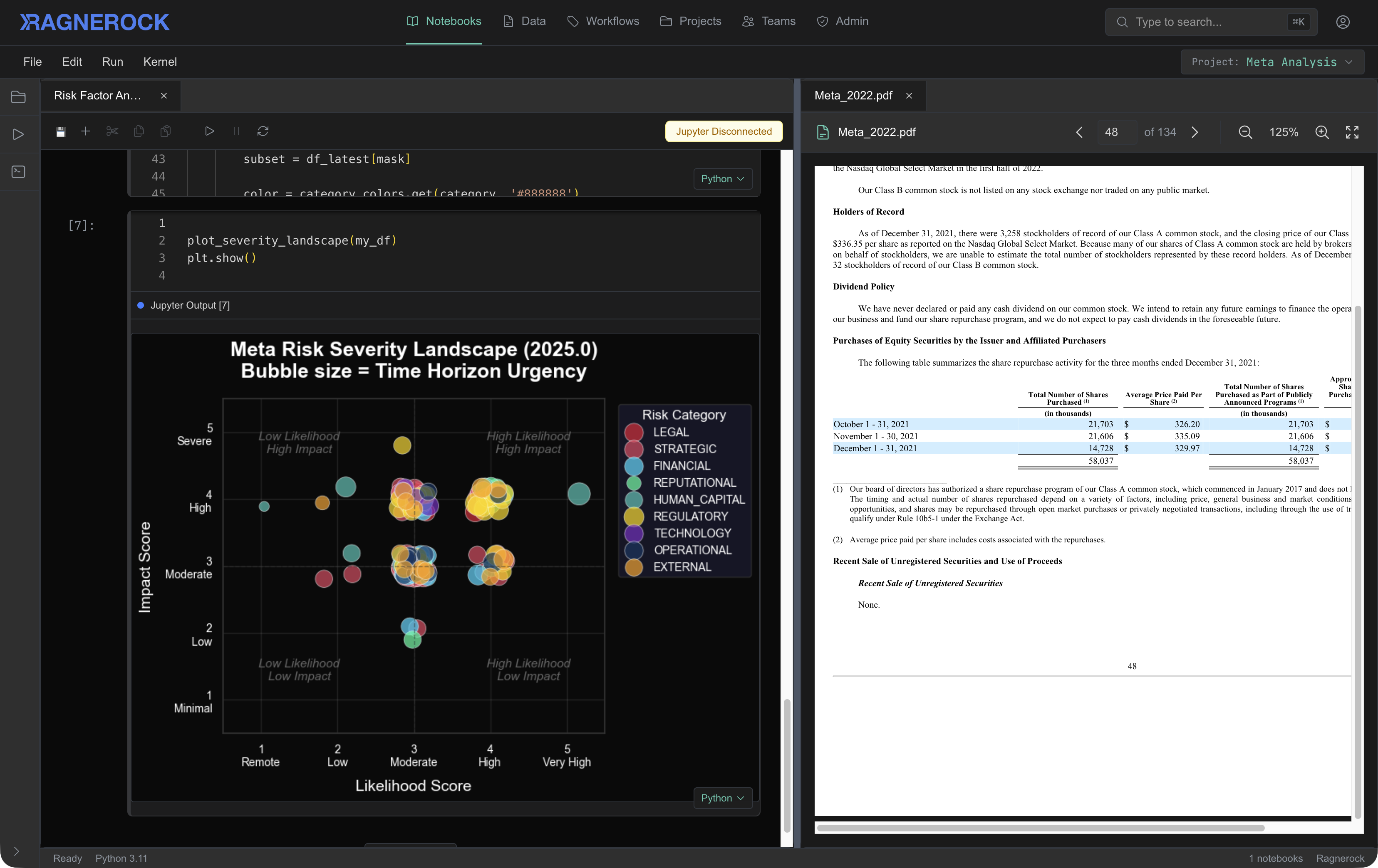
You spend half your time wrangling data instead of studying it. Some hypotheses never get explored because the effort-to-uncertainty ratio is too high. The alternative data vendor you're evaluating charges per-seat fees that don't scale, and their schema doesn't match your research questions.
- Process once, query infinitely. Define your AI workflow to automatically process alternative data as it arrives. The output becomes a queryable research substrate you can join with your existing warehouse.
- Define your own schema. Extract exactly what matters for your research question: sentiment scores, entity mentions, regulatory signals, whatever your hypothesis requires. No vendor lock-in to someone else's data model.
- Replace expensive data products. Build custom data ingress pipelines for sources that would cost a fortune through traditional providers. Process whatever feeds your models, whether news, filings, transcripts, industry reports, tweets, video, or something else.
Run significantly more experiments for the same budget. When a hypothesis doesn't pan out, you've spent days instead of months. When it does, you already have the production pipeline.
Example: Earnings call sentiment pipeline
Ingest transcripts as they're published → extract management sentiment by topic → flag language changes vs. prior quarter → output structured scores to your warehouse → join with position data for signal validation. Defined once as a workflow, runs automatically every earnings season.
Built for data-driven workflows
Ragnerock outputs flow directly to your existing data infrastructure, including Snowflake, Databricks, BigQuery, or your own Postgres DB. Join AI-derived features with any signal in your research stack. The research agent understands SQL and can help you explore the data conversationally before you commit to code.
Give your analysts a head start
Extract
Your analysts are experts at evaluating deals, assessing risk, and synthesizing research. But a significant share of their day goes toward extracting structured information from documents before they can begin the actual analysis. The volume only grows: every new quarter and every new deal means more documents to process.
Ragnerock handles the extraction step so your team can start from structured data. Define what needs to be pulled and the platform processes documents at scale as they arrive. Every output traces back to the specific page and passage it came from. Your team spends their time on judgment calls: evaluating terms, spotting anomalies, forming views, instead of the mechanical work of getting data out of PDFs.
Deal and transaction review
Extract key terms, financial summaries, and material provisions from offering documents, prospectuses, and transaction agreements as they arrive. Your team starts with structured comparisons instead of spending their first hours on manual extraction, whether they're evaluating a new deal, reviewing a portfolio company, or assessing an acquisition target.
Contract and legal analysis
Parse agreements, schedules, and supporting documents at scale. Surface obligations, key dates, non-standard provisions, and risk language so your legal and operations teams can focus on reviewing what matters rather than finding it. The same workflow handles employment agreements, vendor contracts, lease terms, or any other recurring document type your organization processes.
Research and report triage
Process incoming reports and publications at scale. Extract key findings, methodology, estimates, and recommendations. Flag what's relevant to current priorities so your analysts go straight to the material that matters. Works across sell-side research, clinical literature, market studies, competitive intelligence, regulatory guidance, or any domain where your team is drowning in reports that each contain a few pages of signal.
The same approach applies to any recurring document type your firm processes.

"Every insight traced back to source. Every action logged. Every finding defensible."
Make the mandatory cheaper
Monitor
Regulatory obligations require processing and analyzing large volumes of communications, operational records, filings, and other data. This work must be done regardless of cost. The question is whether you do it efficiently.
Ragnerock automates these workflows at a fraction of current costs. Define your own compliance logic (flagging criteria, escalation rules, cross-referencing patterns) and the platform applies it consistently across every communication, trade record, and filing. Every finding is fully traceable to its source.
When regulators ask where a conclusion came from, you won't be scrambling to reconstruct the analysis. The complete audit trail is already there: every message processed, every rule applied, every human review captured.
- Audit trail
- Complete
- Data residency
- BYODB
- Authentication
- SSO
- Encryption
- AES-256
Build proprietary models and signals
Build
Some analytical tasks are central enough to your business that you need a custom model: a classifier tuned to your taxonomy, an extractor for your document types, a scoring model trained on your team's judgments. Building these requires high-quality labeled data at scale, which has traditionally been the bottleneck. Ragnerock's annotation workflows let you use frontier LLMs to generate initial labels, then refine with human review. The same pipeline continues running in production, with full provenance from training examples through to production outputs.
Your taxonomy, enforced
Define any annotation structure with JSON Schema. Your sector classifications, your risk categories, your entity types. The schema is yours.
Label at scale
Use frontier LLMs to generate initial annotations across thousands of documents. Target human review where it matters most.
Training to production, no handoff
Deploy your trained model as an operator in Ragnerock. The annotation pipeline becomes the production pipeline. Same data flow, same provenance, no reimplementation.
See how Ragnerock fits your firm's workflow.
Every organization's data challenges are different. Walk us through yours and we'll show you what Ragnerock can do with it.