The Platform
From raw data to queryable intelligence. One platform.
Ragnerock gives your team four building blocks: AI agents that extract structured data from any source, workflows that chain them into multi-step analysis, a query layer that makes every result instantly searchable, and a notebook environment for exploratory research.
Data-focused AI Agents
Operators
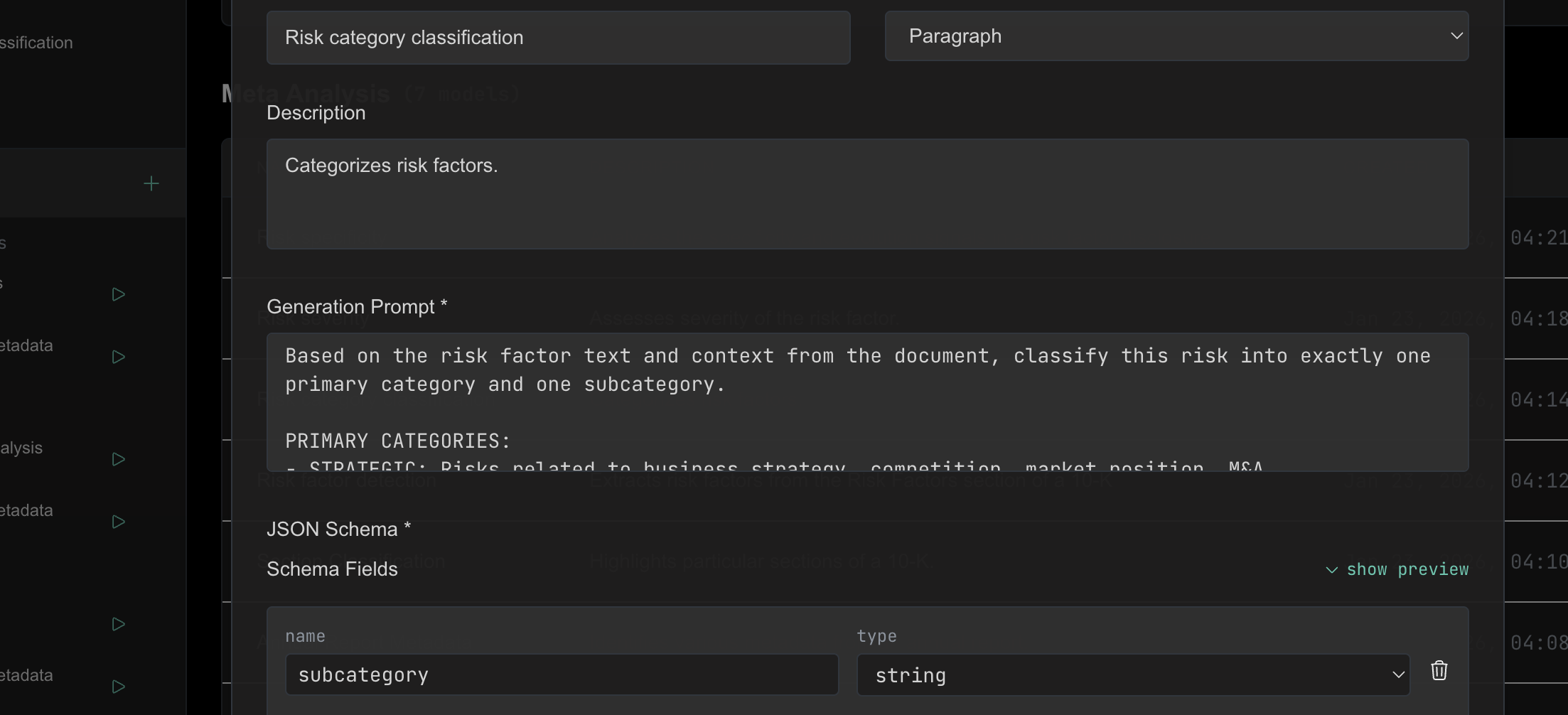
Each operator is an AI agent with a defined data contract: what it receives, what it produces, validated against JSON Schema. Classify documents, extract structured fields, identify risk factors, or define domain-specific extractors. Each operator sees exactly one document and one task. Narrow context by design: the model's attention isn't diluted by irrelevant information. You define the analytical task; Ragnerock enforces the contract.
Learn more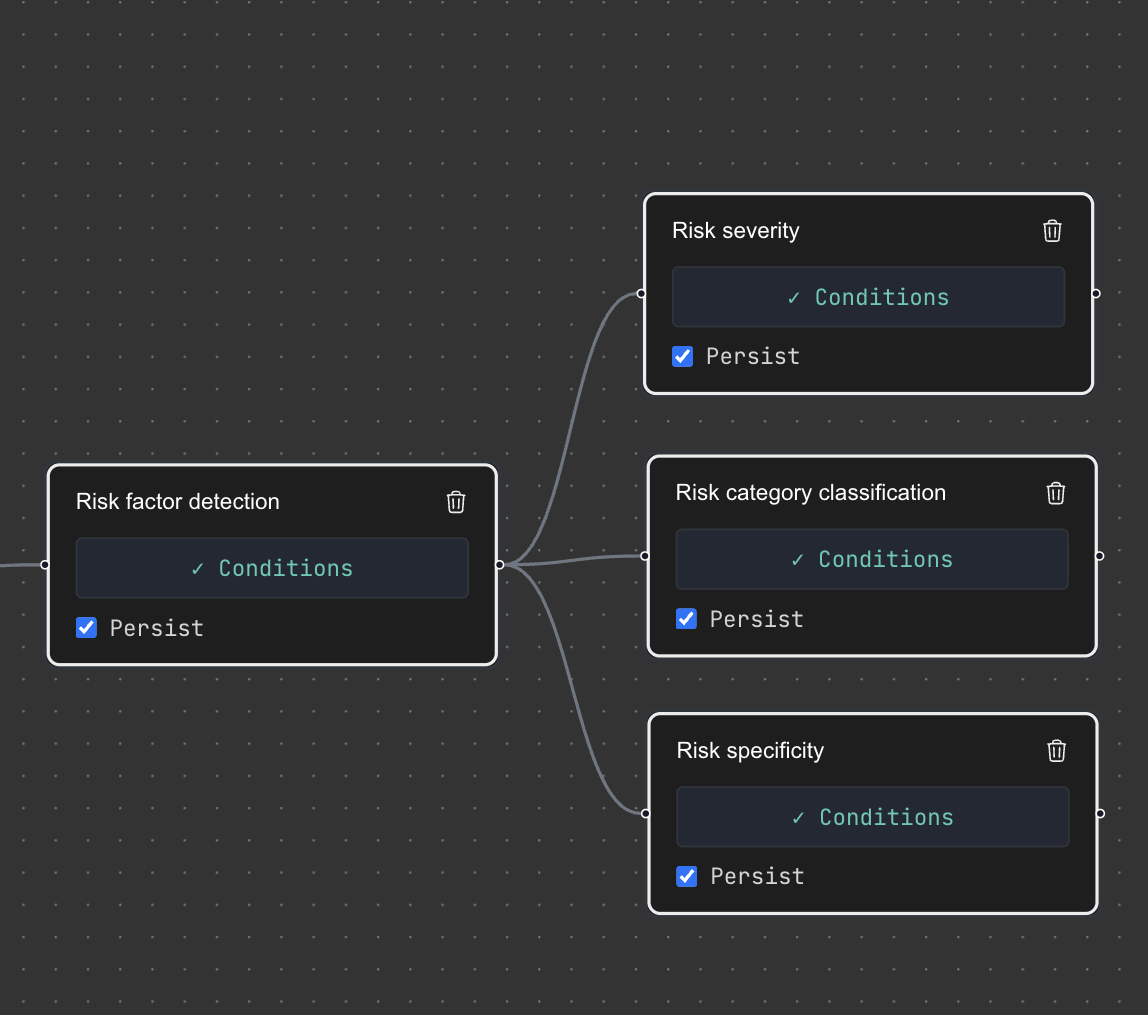
Multi-step Analysis
Workflows
Workflows are DAGs of operators that define your full analytical flow. Go beyond single-step extraction: identify relevant sections of a document, segment them, run specialized analysis on each segment, call external tools, benchmark results. Upstream operators produce structured context that downstream operators consume, so each step builds on validated outputs rather than raw inputs. The entire pipeline is versioned and auditable.
Learn more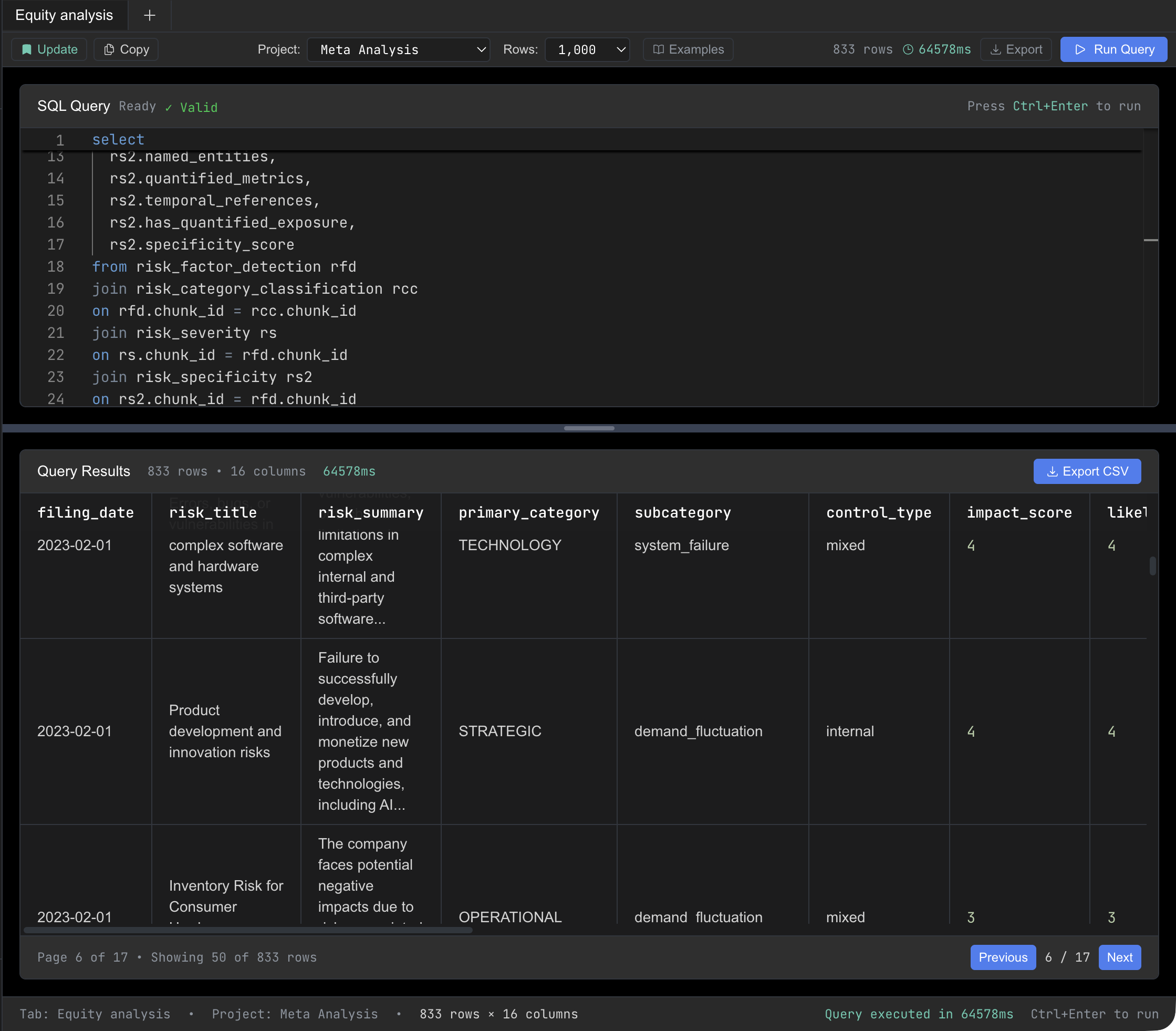
SQL Over AI Outputs
Queries
Every operator's results are exposed as SQL tables. Query, filter, join, and aggregate your AI-derived data with standard SQL, or search semantically when you need flexibility. Millisecond response times on pre-computed annotations. No LLM running at query time. Join AI-derived intelligence with the rest of your data using the syntax your team already knows.
Learn more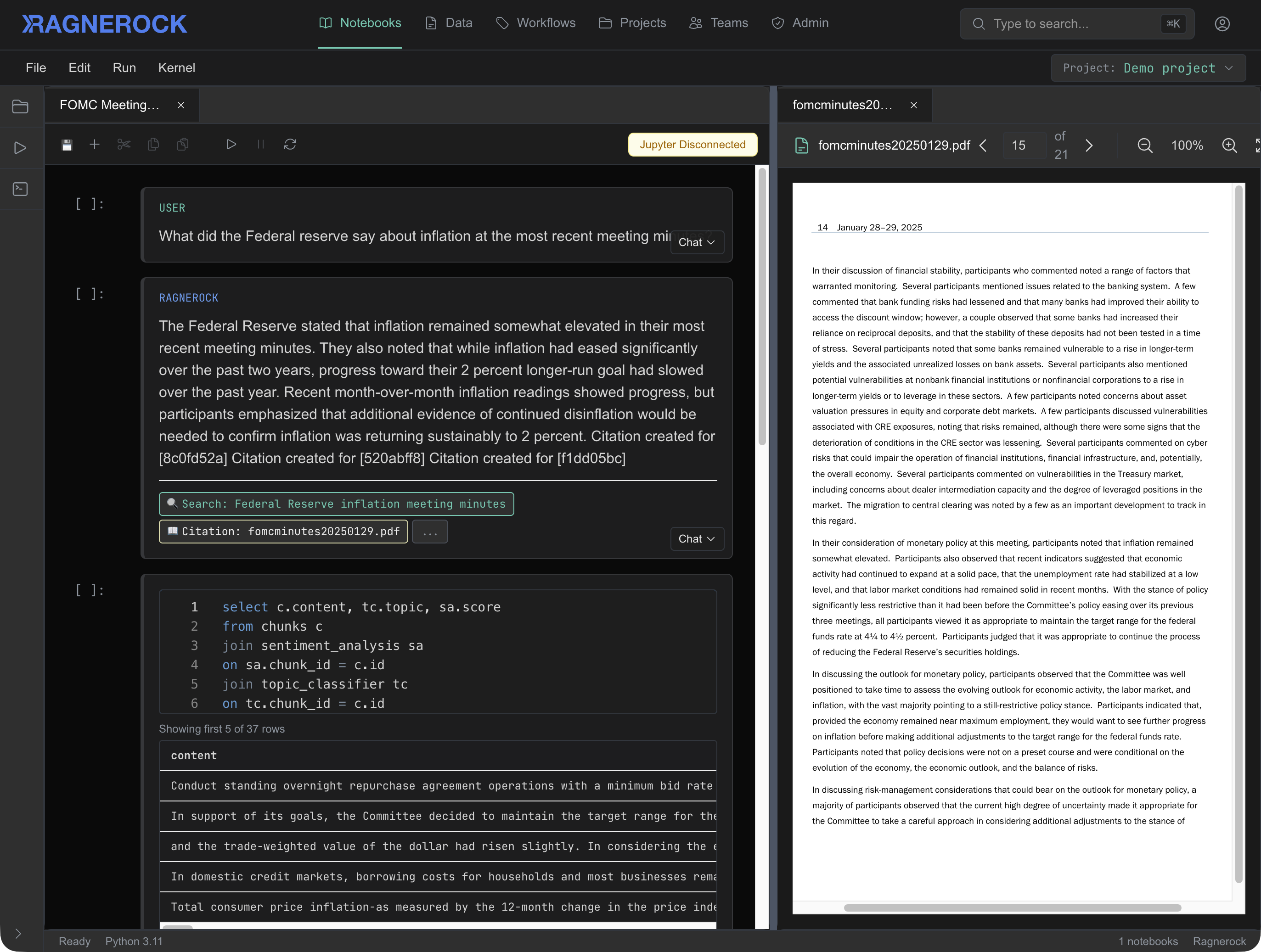
Where Research Happens
Notebooks
Notebooks bridge Ragnerock with your existing research environment. Run SQL queries and pull results directly into Python dataframes. An AI research agent can search across your entire document universe, answer questions with citations, and help you explore data conversationally before you commit to code. Integrates with your existing notebook environment.
Learn moreArchitecture
Process once. Query infinitely.
Most AI data tools run inference on every query. Something like SELECT ai_analyze(text) FROM documents: each row, each query, each time. This is slow (seconds per call), expensive (you're paying for LLM inference on every request), and non-deterministic (the same query can return different results on different days).
Ragnerock takes the opposite approach. AI processing runs once, when data enters the system through a workflow. The results persist as structured, schema-validated annotations. Every query downstream hits pre-computed data at millisecond latency using standard SQL.
Data platforms like Snowflake and Databricks are adding AI features, but their consumption pricing incentivizes inference on every query, the opposite of this model.
The economics follow directly. For data you query regularly (which is most research data), costs scale with data volume and extraction complexity, not with how many times your team queries it. This means a significant reduction in AI-related costs compared to per-query inference.
SELECT ai_analyze(transcript, 'extract sentiment')
FROM earnings_calls
WHERE date > '2025-01-01';SELECT sentiment_score, key_topics, risk_flags
FROM earnings_calls_annotations
WHERE date > '2025-01-01';Integrations
Your data stays in your stack
Ragnerock connects to the AI providers, databases, and cloud storage your firm already uses. Annotation outputs flow directly into your data lake. No vendor lock-in, no data migration, full control.
- AI Providers.
- Connect your existing API keys for OpenAI, Anthropic, Google, or xAI. Use the models you trust without switching providers.
- Databases.
- Export annotation data directly to PostgreSQL, Snowflake, Databricks, or BigQuery. Your structured outputs live where your analytics already run.
- Cloud Storage.
- Store documents in AWS S3, Google Cloud Storage, or Azure Blob Storage. Ragnerock works with your existing buckets and security policies.
Ingest anything
All your data sources
Ragnerock supports common document and data formats, from documents and spreadsheets to web content and databases.
- Text & Markdown
- PDF Documents
- Word Documents
- Excel Spreadsheets
- HTML & Web Scraping
- Image & Video
- Dataframes & CSV
- SQL Databases
See it in action.
Explore the platform yourself, or talk to us about how Ragnerock fits your team's workflow.